PairSpaces for AI/ML
Prototyping in parallel, faster iteration, secure sharing
Working Together from Model to Metrics
Alice and Bob are working together to classify the CIFAR-10 dataset. Alice is working on the training of an ML model and Bob is focused on evaluating the model. They agree where the model output will be located and start working together in parallel.
Let's watch them leverage PairSpaces to work together.
Setting Up
To follow along in your Space, you need to install the following dependencies.
> sudo yum -y install git
> curl -O https://bootstrap.pypa.io/get-pip.py
> python3 get-pip.py --user
> pip install torch torchvision matplotlib scikit-learn streamlitEach Space has its own storage volume available from /space.
> cd /space
> mkdir image-classification
> mkdir worktrees
> cd image-classification
> mkdir data
> mkdir sharedCreate shared/cnn_model.py:
import torch.nn as nn
class CNN(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(3, 32, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.fc = nn.Linear(64 * 8 * 8, 10)
def forward(self, x):
x = self.conv(x)
x = x.view(-1, 64 * 8 * 8)
return self.fc(x)Initial Repository
Set up a new Git repository:
> git init .
> git branch -M mainThis is the initial state of the repository:
image-classification
├── data/
├── shared/
└── cnn_model.py...and make the initial commit...
> git add .
> git commit -m 'feat: initial commit'
[main (root-commit) 9dcb75d] feat: initial commit
1 file changed, 19 insertions(+)
create mode 100644 shared/cnn_model.pySet up Worktrees
# Alice
> git worktree add -b feat/train-cnn ../worktrees/train-cnn
Preparing worktree (new branch 'feat/train-cnn')
HEAD is now at 9dcb75d feat: initial commit
> cd ../worktrees/train-cnn
# Bob
> git worktree add -b feat/eval-metrics ../worktrees/eval-metrics
Preparing worktree (new branch 'feat/eval-metrics')
HEAD is now at 9dcb75d feat: initial commit
> cd ../worktrees/eval-metricsAlice Trains CNN on CIFAR-10
From her worktree Alice adds train_cnn.py...
# train_cnn.py
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
import json
import os
import matplotlib.pyplot as plt
from shared.cnn_model import CNN
# Load data
transform = transforms.ToTensor()
trainset = torchvision.datasets.CIFAR10(root='../data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
testset = torchvision.datasets.CIFAR10(root='../data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False)
# Model + Training
model = CNN()
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
train_loss = []
val_accuracy = []
for epoch in range(5):
model.train()
running_loss = 0.0
for x, y in trainloader:
optimizer.zero_grad()
loss = criterion(model(x), y)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_loss.append(running_loss / len(trainloader))
# Validation
model.eval()
correct = total = 0
with torch.no_grad():
for x, y in testloader:
preds = model(x).argmax(dim=1)
correct += (preds == y).sum().item()
total += y.size(0)
val_accuracy.append(correct / total)
# Save model and metrics
os.makedirs("../shared", exist_ok=True)
torch.save(model.state_dict(), "../shared/cnn.pth")
with open("../shared/metrics.json", "w") as f:
json.dump({"train_loss": train_loss, "val_accuracy": val_accuracy}, f)...and commits her change...
> git add .
> git commit -m "feat: trained CNN and saved metrics"
[feat/train-cnn 9bf39bd] feat: trained CNN and saved metrics
1 file changed, 52 insertions(+)
create mode 100644 train_cnn.pyBob Evaluates and Visualizes the CNN
Bob and Alice agreed to store the model state and metrics at shared/cnn.path and shared/metrics.json, so Bob proceeds to code the evaluation of the model...
# evaluate.py
import torch
import torchvision
import torchvision.transforms as transforms
from shared.cnn_model import CNN
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
import os
# Load model
model = CNN()
model.load_state_dict(torch.load("../shared/cnn.pth"))
model.eval()
# Load test data
transform = transforms.ToTensor()
testset = torchvision.datasets.CIFAR10(root='../data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False)
classes = testset.classes
# Predict
y_true, y_pred = [], []
with torch.no_grad():
for x, y in testloader:
preds = model(x).argmax(dim=1)
y_true.extend(y.numpy())
y_pred.extend(preds.numpy())
# Confusion matrix
cm = confusion_matrix(y_true, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=classes)
disp.plot(cmap="Blues", xticks_rotation="vertical")
plt.title("CNN Confusion Matrix")
plt.savefig("../shared/cnn_confusion.png")...as well as the main entrypoint to the Streamlit application that visualizes the model...
# app.py
import streamlit as st
from PIL import Image
import json
st.title("CNN Evaluation Dashboard")
view = st.sidebar.radio("Select View", ["Training Metrics", "Confusion Matrix"])
if view == "Training Metrics":
with open("../shared/metrics.json") as f:
metrics = json.load(f)
st.line_chart({"Training Loss": metrics["train_loss"]})
st.line_chart({"Validation Accuracy": metrics["val_accuracy"]})
elif view == "Confusion Matrix":
st.image("../shared/cnn_confusion.png")...finally commits his changes...
> git add .
> git commit -m "feat: evaluate CNN and show confusion matrix"
[feat/eval-metrics e4e408b] feat: evaluate CNN and show confusion matrix
create mode 100644 app.py
create mode 100644 evaluate.pyShare the Model for Feedback
Alice and Bob can now merge their work and present it to their team for feedback. Alice manages merging their branches:
> cd ../../image-classification
> git worktree add ../worktrees/presentation -b presentation main
Preparing worktree (new branch 'presentation')
HEAD is now at 9dcb75d feat: initial commit
> cd ../worktrees/presentation
> git fetch ../train-cnn feat/train-cnn
From ../train-cnn
* branch feat/train-cnn -> FETCH_HEAD
> git merge FETCH_HEAD -m "merge: train CNN"
Updating 9dcb75d..9bf39bd
Fast-forward (no commit created; -m option ignored)
train_cnn.py | 52 ++++++++++++++++++++++++++++++++++++++++++++++++++++
1 file changed, 52 insertions(+)
create mode 100644 train_cnn.py
> git fetch ../eval-metrics feat/eval-metrics
From ../eval-metrics
* branch feat/eval-metrics -> FETCH_HEAD
> git merge FETCH_HEAD -m "merge: evaluation and dashboard"
Merge made by the 'ort' strategy.
app.py | 16 ++++++++++++++++
evaluate.py | 33 +++++++++++++++++++++++++++++++++
2 files changed, 49 insertions(+)
create mode 100644 app.py
create mode 100644 evaluate.pyFrom Bob's local machine he uses the PairSpaces CLI to open a port from the Space...
> pair space SPACE_ID --port 8501
Your Space is now available on port 8501, however, you must be authenticated in PairSpaces to access. Visit https://pairspaces.com/pairs/SPACE_ID to access your Space from this port....and from the Space, Alice serves the Streamlit application to the team...
> python3 train_cnn.py
100.0%
> python3 evaluate.py
> streamlit run your_app.py --server.address=0.0.0.0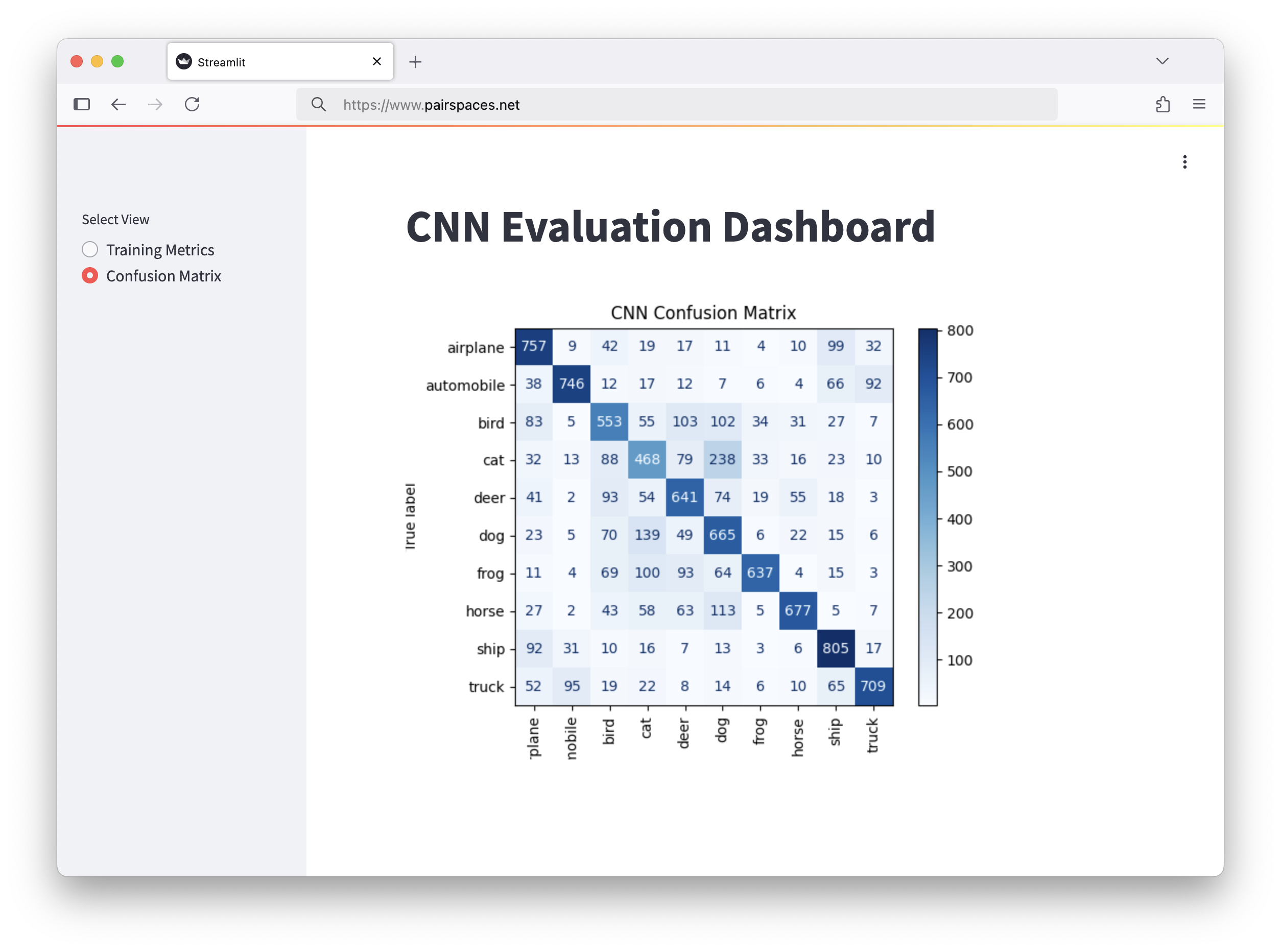
Scale Your AI/ML Development with Real-time Collaboration
PairSpaces supports the same workflows you use when developing AI/ML models. What's different is how PairSpaces enables real-time feedback using Git worktrees. This makes it possible for all your team to work together, and that makes model development faster, cheaper, and better than ever before.
Try PairSpaces now.